Python 函数式编程
什么是函数式编程
本节课我们将介绍函数式编程的特性。虽然我们没有称之为函数式编程,因为 Python 并非一门函数式编程语言。此外,查阅了许多 Python 编程书籍,在介绍 Python 函数式编程时,涉及的内容也相对较少,主要是介绍了函数式编程特性的几个函数�。因此,我们最终决定不将其称为函数式编程,因为该领域实在是太庞大了。因此,我们将只讨论函数式编程的特性。
在本节中,我们将主要介绍函数式编程的第一个特性:什么是函数式编程?函数式编程的定义是这样的:代码中的每一块都是不可变的,都由纯函数的形式组成。那么这里的纯函数指的是什么呢?纯函数就是指函数本身是相互独立的,互不影响。对于相同的输入,总会有相同的输出,而且没有任何副作用。虽然这样说有些晦涩,但我们将通过代码演示副作用是什么意思。
我们来创建一个名为 function_program 的 Python 文件。在这个文件中,我们将创建一个函数,该函数的作用是将列表中的每个元素都乘以2,即使它们加倍。我们将这个函数命名为 doubler,代码如下:
# 定义一个函数 doubler,参数为列表 l
def doubler(l):
# 遍历列表 l 中的每个元素,并对其进行操作
for item in range(0, len(l)):
# 将当前元素乘以2
l[item] *= 2
# 返回操作后的列表 l
return l
# 创建一个列表 list_value,包含元素 1、2、3、4、5
list_value = [1, 2, 3, 4, 5]
# 调用 doubler 函数,并输出结果
print(doubler(list_value))
输出结果:
[2, 4, 6, 8, 10]
运行结果是 2、4、6、8、10。接着我们再次调用这个函数,代码如下:
# 定义一个函数 doubler,参数为列表 l
def doubler(l):
# 遍历列表 l 中的每个元素,并对其进行操作
for item in range(0, len(l)):
# 将当前元素乘以2
l[item] *= 2
# 返回操作后的列表 l
return l
# 创建一个列表 list_value,包含元素 1、2、3、4、5
list_value = [1, 2, 3, 4, 5]
# 调用 doubler 函数,并输出结果
print(doubler(list_value))
print(doubler(list_value))
输出结果:
[2, 4, 6, 8, 10]
[4, 8, 12, 16, 20]
看到结果变成了4、8、12、16、20。这说明这个函数不符合函数式编�程的条件,因为对于相同的输入,两次输出的结果不同,这就产生了副作用。那么我们应该如何修改这段代码呢?我们使用函数式编程的方式来修改这个函数。我们再次定义 doubler,传递一个参数 l。在操作之前,我们首先创建一个新的空列表 new_list。然后,我们遍历列表l中的每个元素 item,将 item 乘以2,并将结果追加到 new_list 中。最后,我们返回这个新的列表 new_list。代码如下:
# 定义一个函数 doubler,参数为列表 l
def doubler(l):
# 创建一个新列表 new_list,用于存储处理后的结果
new_list = []
# 遍历列表 l 中的每个元素 item
for item in l:
# 将每个元素 item 乘以 2,并将结果追加到 new_list 中
new_list.append(item * 2)
# 返回处理后的新列表 new_list
return new_list
# 创建一个列表 list_value,包含元素 1、2、3、4、5
list_value = [1, 2, 3, 4, 5]
# 分别调用 doubler 函数两次,并输出结果
print(doubler(list_value))
print(doubler(list_value))
输出结果:
[2, 4, 6, 8, 10]
[2, 4, 6, 8, 10]
当我们再次调用这个函数时,输出的结果是一致的,没有产生副作用。至此,我们介绍了函数式编程的概念。如果你对函数式编程比较感兴趣,那么你可以学习一门函数式编程语言,比如 Lisp、Scala 等。在这里,我们主要介绍了函数式编程的特性,因为 Python 是支持函数式编程的。
函数式编程map()函数
下面我们将介绍函数式编程相关的三个函数:map、filter 和 reduce。首先,我们将总体了解这三个函数的作用。然后,我们将使用表情图描述来分别介绍它们的功能。
首先是 map 函数。map 函数接受两个参数:第一个参数是一个函数,称为 cook;第二个参数是一个可迭代对象,比如列表或字典。map 函数的作用是将可迭代对象中的每个元素依次应用到 cook 函数上。例如,如果 cook 函数的功能是烹饪食物,那么 map 函数将列表中的每个元素传递给 cook 函数,并生成相应的食物。如下图所示:

��举例来说,列表中的元素分别是奶牛、马铃薯、鸡肉和玉米,经过 cook 函数处理后,分别变成了汉堡、薯条、鸡腿和爆米花。当列表中的每个元素都被 cook 函数处理后,map 函数执行完毕。
接下来是 filter 函数。filter 函数同样接受两个参数:第一个参数是一个函数,例如 isVegetarian,用于判断是否是蔬菜;第二个参数是一个可迭代对象。filter 函数的作用是依次将可迭代对象中的每个元素传递给指定的函数,并根据函数的返回值来过滤元素。例如,对于列表中的元素,如汉堡、薯条、鸡腿和爆米花,根据 isVegetarian 函数的判断,只有薯条和爆米花被保留下来。如下图所示:
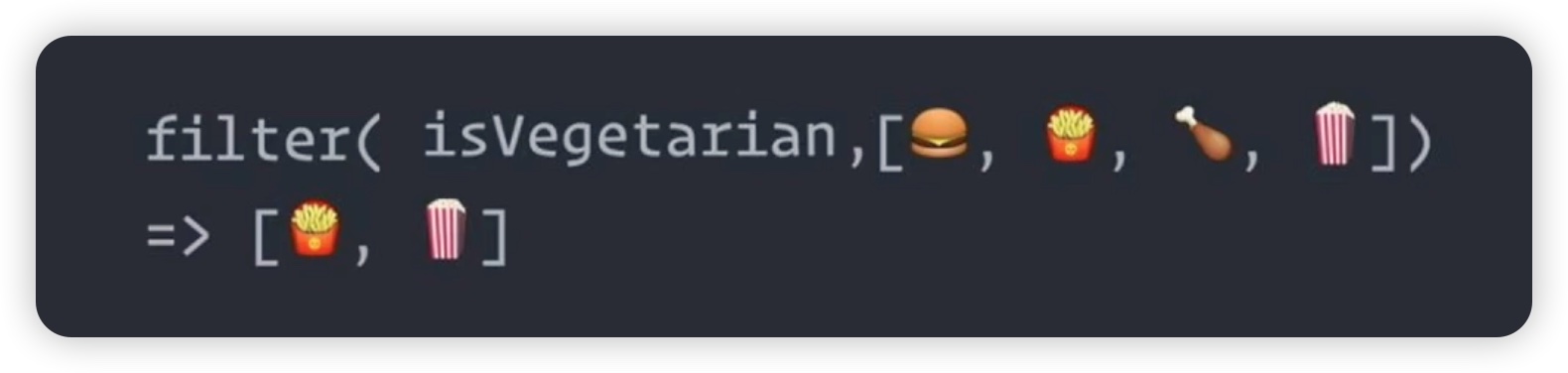
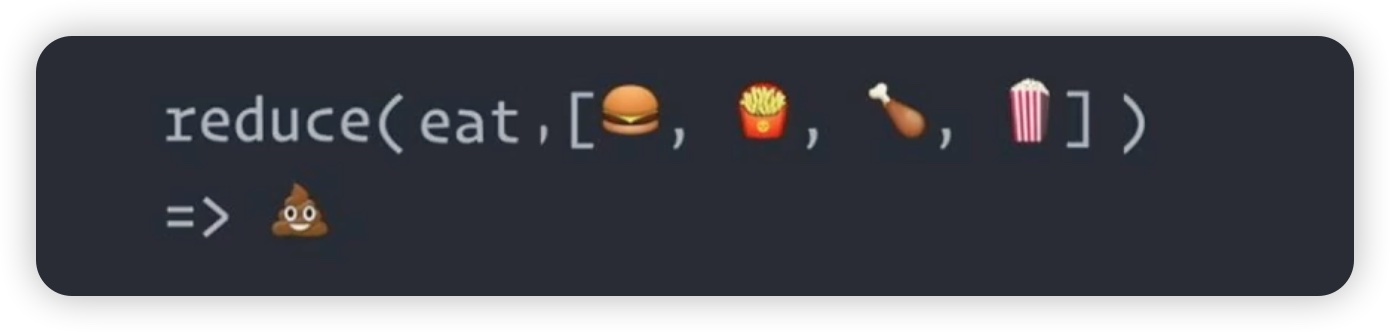
最后是 reduce 函数。reduce 函数也接受两个参数:第一个参数是一个函数,例如 eat;第二个参数是一个可迭代对象,通常是一个列表。reduce 函数的功能是将可迭代对象中的元素依次传递给指定的函数,并生成一个最终的结果。例如,将列表中的元素依次传递给 eat 函数,它的功能是将第1个元素和第2个元素传递给eat,然后生成一个结果,再将这个结果和第3个元素鸡腿,再传递eat,又生成一个结果,接下来再将这个结果和爆米花相结合,再次传递给eat,最终生成了一个最后的结果,在我们这里呢,这个函数最终就生成了一坨这样的东西。
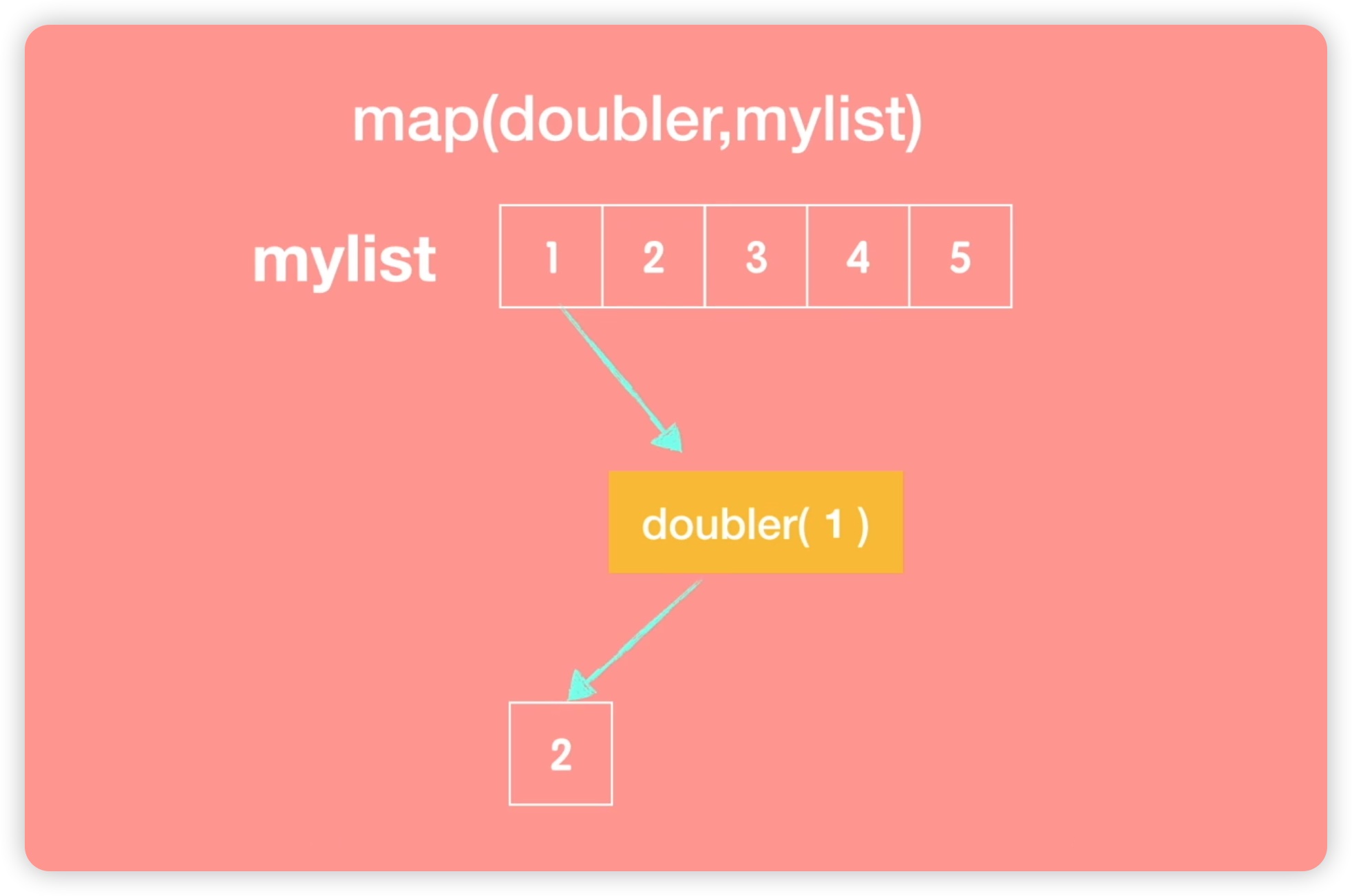
下面我们将分别介绍这三个函数。首先��是 map 函数。map 函数有两个参数:第一个参数是函数名称,这里我们称之为 doubler。这个函数用于实现对给定数字的二倍求解。第二个参数是一个列表,我们称之为 my_list。如下图所示:

我们以一个例子来说明 map 函数的工作原理。假设我们有一个列表 my_list 包含数字 1 到 5。通过 map 函数,我们将列表中的每个元素依次传递给 doubler 函数进行操作。首先, doubler 函数将参数设为 1,经过运算后输出结果为 2;如下图所示:
接着参数变为 2,输出结果为 4;依此类推,直到处理完所有元素,最终生成的结果为 2、4、6、8、10。
接下来,我们在代码中演示 map 函数的使用。我们创建一个新的 Python 文件,命名为 map.py。首先定义一个函数 doubler,该函数接收一个参数 x,将其乘以 2 并返回结果。然后,我们创建一个列表 list_value,其值为 1 到 5。接下来使用 map 函数,将列表中的每个元素依次应用到 doubler 函数上,并将结果保存在变量 result 中。最后,通过 list 函数将 result 转换为列表并输出结果。代码如下:
def doubler(x):
x *= 2
return x
list_val = [1,2,3,4,5]
result = map(doubler,list_val)
print(list(result))
输出结果:
[2, 4, 6, 8, 10]
在代码中,我们还使用了 lambda 表达式来定义 doubler 函数,使代码更加简洁。lambda 表达式可以代替单一功能的简单函数定义。我们将 doubler 函数改写为 lambda 表达式,并将其直接传递给 map 函数进行处理。代码如下:
def doubler(x):
x *= 2
return x
list_val = [1,2,3,4,5]
result = map(lambda x:x*2,list_val)
print(list(result))
无论是使用普通函数定义还是 lambda 表达式,都能得到相同的输出结果。因此,map 函数经常与 lambda 表达式结合使用,以便简化代码并提高效率。
函数式编程filter()函数
接下来我们将探讨第二个函数,即filter函数。该函数同样接受两个参数:第一个参数是函数名称(例如这里是is_odd),用于判断是否为奇数;第二个参数是一个可迭代对象(在这里是一个列表)。我们来看一下filter函数的运作方式。给定一个列表mylist包含数字1至5。函数is_odd用于判断一个数字是否为奇数。在调用filter函数时,每个mylist中的元素都会依次传递给is_odd函数进行判断。开始调用时,首先传递第一个元素1给is_odd,由于1是奇数,因此将其输出。然后是第二个元素2,由于2不是奇数,因此没有输出。接着是下一个元素,同样没有输出。最终,使用filter函数过滤掉的结果为1、3、5。如下图所示:
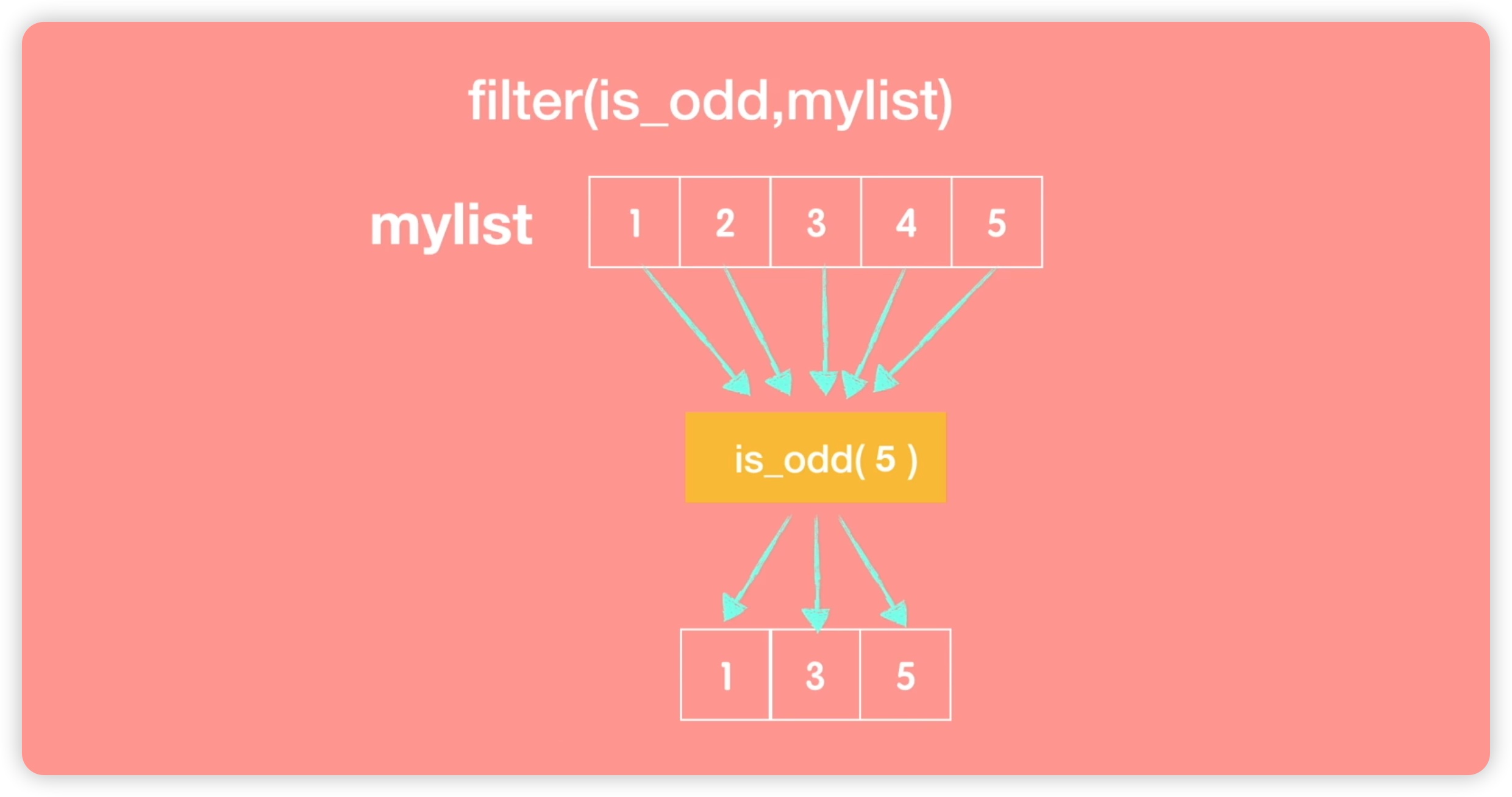
接下来我们将在代码中演示filter函数的使用。我们创建一个新的Python文件,命名为filter。首先定义一个函数is_odd,用于判断一个数是否为奇数。代码如下:
# 定义一个函数is_odd,用于判断一个数是否为奇数
def is_odd(x):
return x % 2 == 1 # 如果x除以2的余数为1,则返回True,表示是奇数,否则返回False
# 创建一个包含数字1至5的列表list_value
list_value = [1, 2, 3, 4, 5]
# 调用filter函数,第一个参数是函数名is_odd,用于判断奇数,第二个参数是列表list_value
result = filter(is_odd, list_value)
# 将filter对象转换为列表并打印结果
print(list(result))
输出结果:
[1, 3, 5]
结果输出了1、3、5,2和4被过滤掉了。这就是filter函数的作用。同样地,is_odd函数也可以用lambda表达式来简化,只需一个参数x,然后判断x是否为奇数。运行结果依然是1、3、5。代码如下:
# 定义一个函数is_odd,用于判断一个数是否为奇数
def is_odd(x):
return x % 2 == 1 # 如果x除以2的余数为1,则返回True,表示是奇数,否则返回False
# 创建一个包含数字1至5的列表list_value
list_value = [1, 2, 3, 4, 5]
# 用lambda表达式来简化
result = filter(lambda x:x%2==1,list_value)
# 将filter对象转换为列表并打印结果
print(list(result))
这就是filter函数与lambda表达式结合的示例。
函数式编程reduce()函数
接下来我们将介绍最后一个函数,即reduce函数。与前面的函数相比,reduce函数稍微有些难以理解。它同样接受两个参数:第一个参数是一个函数(比如这里是add),用于计算两个数的和;第二个参数是一个可迭代对象,通常是一个列表。
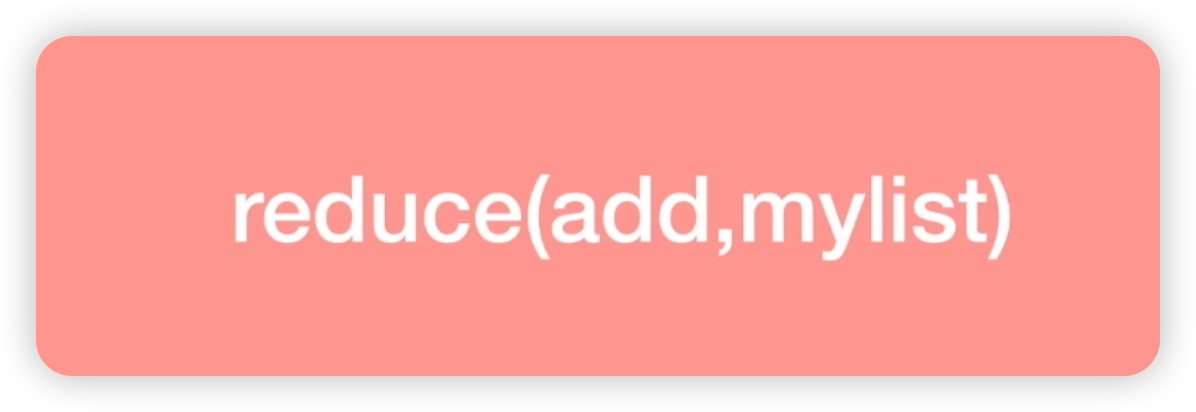
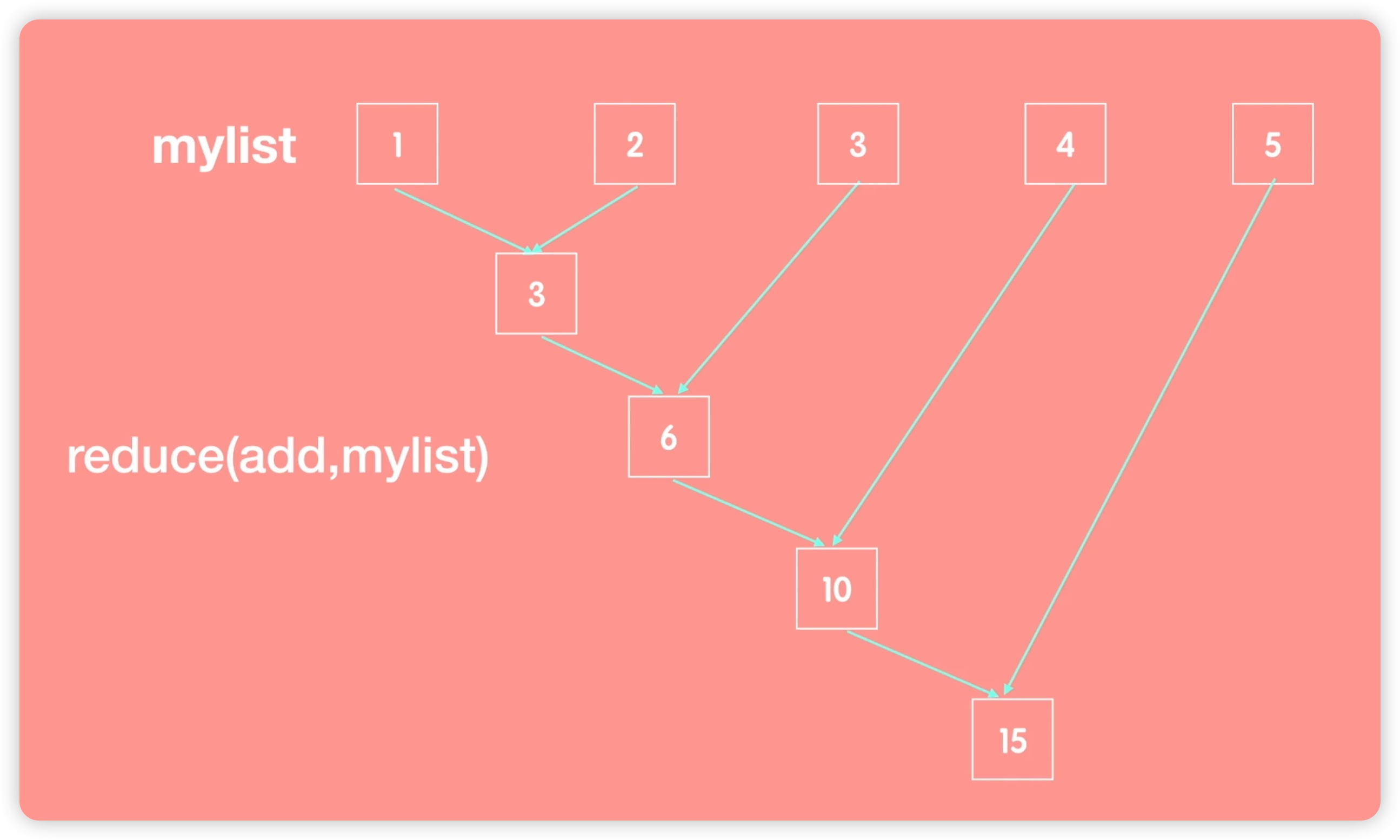
让我们来看看reduce函数是如何工作的。假设我们有一个列表mylist包含数字1至5。如果我们对其使用add函数进行操作,即求两个元素的和,那么它的操作过程是怎样的呢?首先,将mylist中的第一个元素和第二个元素传递给add函数,相加得到3。然后,将生成的结果与第三个元素一起传递给add函数,得到6。接着,将这个结果6与下一个元素相加,传递给add函数得到10,然后再与下一个元素相加,最终结果为15。这就是reduce函数的工作原理。如下图所示:
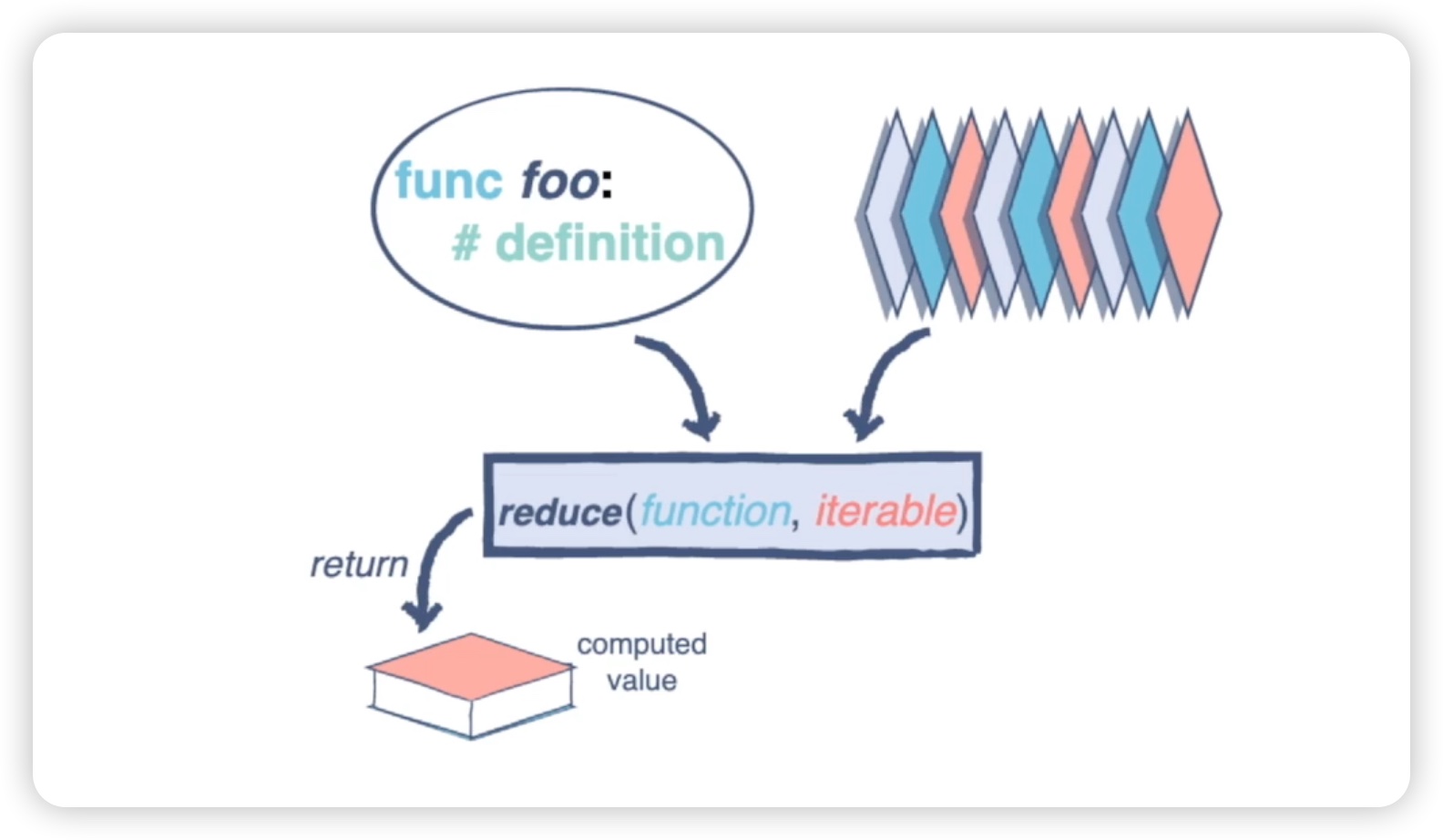
如果我们将可迭代对象比作一张张纸,而reduce函数的结果就是将这些纸合并起来,形成一个最终的结果,类似于合成一本书。如下图所示:
接下来我们在代码中演示一下reduce函数。我们新建一个Python文件,命名为reduce。首先定义一个函数add,用于计算两个数之和,该函数有两个参数x和y,然后直接返回它们的和。接着定义一个列表list_value,包含数字1至5。然后我们使用reduce函数。在Python 3版本中,reduce函数已经不是一个内置函数了,而是被移到了一个名为functools的模块中。因此,在使用reduce函数时,需要从functools模块中导入它。我们从functools模块中导入reduce函数,并将其用于求和操作。reduce函数的第一个参数是函数名称add,第二个参数是可迭代对象list_value。代码如下��:
from functools import reduce
def add(x,y):
return x+y
list_value = [1,2,3,4,5]
# result = reduce(add,list_value)
result = reduce(lambda x,y:x+y,list_value)
print(result)
输出结果:
15
运行结果输出为15。这就是reduce函数与其它两个函数的区别。使用map函数时,结果是一个map对象;使用filter函数时,结果是一个filter对象,需要使用list函数转换为列表;而使用reduce函数时,其作用是用于求和,最终生成的是一个和的结果,因此直接输出即可。值得注意的是,在使用reduce函数时,需要��从functools模块中导入该函数,然后才能使用它。这就是reduce函数的工作原理。
三个函数与列表生成式区别
在本节中,我们将介绍三个函数与列表生成式之间的区别。在上一节课程中,我们已经讨论了函数式编程中的几个函数。细心的学习者可能会注意到,在使用这些函数操作列表时,我们也可以使用列表生成式来实现相应的功能。本节将详细介绍函数式编程中的几个函数与列表生成式之间的区别。
首先,让我们编写代码,用列表生成式的方式实现使用map函数和filter函数所实现的功能。我们找到了map.py文件,现在让我们来运行一下。在这里,map函数的功能是将列表中的每一个元素都乘以2,使其变为原来的二倍。结果就是2、4、6、8、10。接下来,我们用列表生成式的方式来实现同样的功能。我们有一个列表list_value,我们需要将其中的每一个元素都乘以2。代码如下:
def doubler(x):
x *= 2
return x
list_val = [1,2,3,4,5]
# result = map(doubler,list_val)
result = map(lambda x:x*2,list_val)
print(list(result))
print([ x*2 for x in list_val])
输出结果:
[2, 4, 6, 8, 10]
[2, 4, 6, 8, 10]
输出结果为2、4、6、8、10,与map函数相同。
接着,我们再来看使用filter函数的情况。我们找到了filter.py文件,让我们来运行一下,看一下这个函数实现了什么功能。filter函数的功能是在��列表过滤掉不满足条件的元素,保留满足条件的元素。这个条件是判断元素是否为奇数,如果是奇数,则结果为True,保留该元素;否则结果为False,过滤掉该元素。我们使用列表生成式来实现同样的功能。我们添加一个if语句来判断条件。如果条件满足,即元素为奇数,我们就将该元素加入到最终的列表中。代码如下:
def is_odd(x):
return x % 2 == 1
list_value = [1,2,3,4,5]
# result = filter(is_odd,list_value)
result = filter(lambda x:x%2==1,list_value)
print(list(result))
print([x for x in list_value if x%2==1])
输出结果:
[1, 3, 5]
[1, 3, 5]
最后,输出结果为1、3、5,与filter函数的功能相同。
下面我们来总结一下函数式编程的两个函数,map函数和filter函数,与我们使用列表生成式之间的区别。首先,让我们来看一下它们在形式上的区别。对于列表生成式,我们的写法是这样的:我们通过for循环遍历range(100),然后将获取到的i值使用str函数转化为字符串,最终生成的列表是一个包含从0到99的字符串。这是列表生成式的形式。那么,如果要使用map函数来实现同样的功能呢?也是非常简单的。map函数有两个参数,第一个参数是函数名称,第二个参数是range(100),即将0到99的每个数都传递给这里的str函数进行转换。最后,生成的是一个map对象,如果要将其转化为列表,我们可以在外层包裹一个list函数。如下图所示:

从形式上来看,这两种方式的区别在于,使用列表生成式的方式更易于理解。因此,通常情况下我们会选择使用列表生成式的方式。
接下来,我们再来看另一种形式。在下面的列表生成式中,我们使用了一个for循环来依次遍历my_list列表,然后将生成的结果传递给my_function这个函数。第一行是有x,而第二行则使用了一个下划线来代替这个x,下划线在这里起到占位符的作用。而我们的my_function函数是自定义的函数。对于这种形式,如果我们要使用map函数来实现呢?它的实现效果是这样的:一个map函数,函数里面有两个参数,第一个就是my_function,而第二个参数则是my_lists这个列表。对于实现同样的功能,这两种方式通常我们会选择使用map函数的方式。如下图所示:

因为在这里我们定义了一个新的函数叫做my_function,这个函数是我们之前已经定义好的。所以在形式上,我们看起来更加直观。而在使用列表生成式的时候,我们还需要传递参数,比如说是x或者是下划线等等。因此,在语义上使用map函数更为清晰,更为明了�。
接下来我们再来看在运行效率上的对比。我们将比较这两个函数,看一下哪个运行更快。

让我们来编写代码,在代码中演示一下。我们创建一个名为compare的Python文件。为了实现对比效果,我们需要引入time模块,并分别记录它们的运行时间。另外,为了对比它们的运行效率,我们还需要引入一个名为timeit的模块。
我们将使用timeit模块下的timeit方法。这个方法接受一个字符串作为参数,字符串的内容就是我们需要运行的代码。首先,我们来编写使用列表生成式的形式:通过for循环遍历range,然后对每个值使用str进行转换。由于程序运行非常快,我们再给它添加一个次数,假设我们设置为10000次。将结果赋值给一个变量,命名为list_time,然后输出这个时间。
import timeit
list_time = timeit.timeit('[str(i) for i in range(100)]',number=10000)
print(list_time)
输出结果:
0.265598783
接着,我们使用map函数的形式。第一个参数是str,第二个参数是range。同样地,我们也运行10000次,并将结果赋值给map_time,然后输出。
import timeit
map_time = timeit.timeit('map(str,range(100))',number=10000)
print(map_time)
输出结果:
0.00494831499999998
结果显示,使用列表生成式的形式运行时间为0.27秒,而使�用map函数的形式仅用时0.05秒。这个差距是非常大的。可能会有一些小伙伴说,你这里生成了一个列表,而使用map函数生成的是一个map对象,这样不公平。那么我们再复制一份,将其转化为列表,使用list函数。然后再次输出结果。
import timeit
map_list_time = timeit.timeit('list(map(str,range(100)))',number=10000)
print(map_list_time)
输出结果:
0.19432597000000001
第一种形式是列表生成式,输出时间为0.26秒。第二种方式是使用map函数生成map对象,它的运行时间非常短。而第三种形式是使用map函数,然后转化为列表,运行时间为0.19秒。从这个运行效率上我们可以看出,单独使用map函数生成map��对象,它的运行时间最短。而将这个结果转化为列表时,这个时间和使用列表生成式的时间相差不多,但它的效率仍然更高。为什么会这样呢?因为返回的是一个map对象,而map对象是一个迭代器。迭代器的知识我们会在后面的章节中再详细介绍。小伙伴们可以将其想象为一个可以迭代的容器。当我们使用列表生成式时,会将所有的元素一起输出,占用的内存就会较大。而迭代器不是一次性输出的,而是循环一次,输出一次,循环一次,输出一次,因此占用的内存较小,导致运行时间非常短。因此,从效率上讲,map函数更高效。
通过以上的对比我们发现,使用函数式编程的几个函数与我们的列表生成式各有优劣。那么我们应该如何选择呢?
在大多数情况下,如果能使用列表生成式实现的功能,那么我们尽量使用列表生成式,因为它的代码更加简短,更加易懂。在少数情况下,例如数据量较大时,我们会更多地考虑效率,此时会使用map函数或filter函数。还有一种情况是当函数已经定义好了,这个时候我们更倾向于使用map函数,因为它的代码更易读。除了以上两种情况,还有一种情况是当逻辑特别复杂时,无论是使用列表生成式还是使用函数式编程的几个函数,编写的代码都会让人摸不着头脑,此时我们推荐使用for循环,虽然效率稍低,但代码更可读。
函数是一等公民
本节我们来介绍一下函数是一等公民的概念。为什么说函数是一等公民呢?主要是因为它具有以下特性:
-
函数可以像普通变量一样进行赋值。也就是说,我们可以将函数赋值给一个变量,并且在后续的代码中使用这个变量来调用函数。
-
函数可以作为参数进行传递。这意味着我们可以将一个函数作为另一个函数的参数进行传递,并在函数内部进行调用。
-
函数也支持在函数内部嵌套函数的定义。也就是说,我们可以在一个函数内部定义另一个函数,并在外部函数中调用内部函数。
-
函数还可以作为返回值。这意味着一个函数可以执行完毕后返回另一个函数,而不仅仅是返回一个数值或其他类型的数据。
下面我们将在代码中演示函数的这几种特性。我们将创建一个Python文件,命名为first_citizen。首先,我们来看第一个特性:赋值。我们定义一个函数func,接收一个参数message,并直接将其输出。然后,我们将这个函数赋值给一个变量send_message。注意,在赋值时我们不需要加括号,因为这是一个函数对象。现在,我们可以使用这个变量send_message来调用函数,相当于调用func。代码如下:
# 赋值
def func(message):
print(f"Got a message:{message}")
send_message = func
print(func)
send_message("welcome to DaXiong course") # func()
输出结果:
<function func at 0x1039efeb0>
Got a message:welcome to DaXiong course
接着,我们来看第二个特性:函数作为参数。我们定义了一个函数get_message,它接收一�个参数message,然后返回一个字符串。然后,我们定义了另一个函数call,它有两个参数,第一个参数是函数func,第二个参数是message。在函数内部,我们将函数对象func加括号表示调用,并将message作为参数传递给它。现在,我们调用函数call,将函数get_message作为参数传递给func,并传递一个字符串作为message参数。
# 作为参数
def get_message(message):
return f"Got a message:{message}"
def call(func,message):
print(func(message))
call(get_message,"welcome to DaXiong course")
输出结果:
Got a message:welcome to DaXiong course
接下来,我们看第三个特性:支持嵌套。支持嵌套指的是在函数内部再定义一个函数并进行调用。我们先定义一个函数func,同样接受一个参数message。在函数内部,我们再定义一个函数get_message,同样接受一个参数message,并输出。然后,我们在func函数中返回get_message函数。需要注意�的是,内部定义的函数get_message只能在外层函数中调用,而不能在外部调用。接着,我们调用func函数并传递一个参数message,然后程序会依次执行函数体内的内容,最终输出函数的返回值。代码如下:
# 支持嵌套
def func(message):
def get_message(message):
print(f"Got a message:{message}")
return get_message(message)
func("welcome to DaXiong course")
输出结果:
Got a message:welcome to DaXiong course
接下来,我们看最后一个特性:函数可以作为返回值。在这种情况下,函数体内部会返回一个函数。我们先定义一个函数func,内部再定义一个函数get_message,然后在函数体中返回get_message函数。当调用func函数时,程序会执行函数体内的内容,创建一个函数变量get_message,但不会执行函数体下面的内容,而是直接返回一个函数对象给调用者。这个返回的函数对象可以赋值给一个变量,然后调用它。最终,我们通过输出函数的返回值来验证函数作为返回值的特性。
# 返回值
def func():
def get_message(message):
return f"Got a message:{message}"
return get_message
send_message = func() # send_message = get_message
message_string = send_message("welcome to DaXiong course") # get_message()
print(message_string)
输出结果:
Got a message:welcome to DaXiong course
这些特性使得函数在Python中成为一等公民,即可以像普通变量一样进行操作,可以作为参数进行传递,支持嵌套定义,也可以作为返回值。
函数装饰器
本节我们将介绍函数装饰器。或许你对装饰器这个词并不熟悉,但你一定知道装饰品。就像在圣诞节我们装饰圣诞树一样,对于这棵树来说,我们只是添加了一些装饰,但它本身并没有改变。对于下图这个人而言,她本身没有发生任何改变,只是说它自身加了一些装饰品,如下图所示:
类似地,对于一个函数而言,它本身并没有发生任何变化,我们只是在其周围加上了一些装饰。举个例子,在计算程序运行时间时,通常我们会在函数执行前后记录时间,然后计算时间差来得到程序的运行时间。这种方式需要在每个函数使用前后执行相同的操作,如果需要统计多个程序的运行时间,代码会显得非常冗余。代码如下图:

再来看一个例子,对于一个商城系统,代码如下下图:
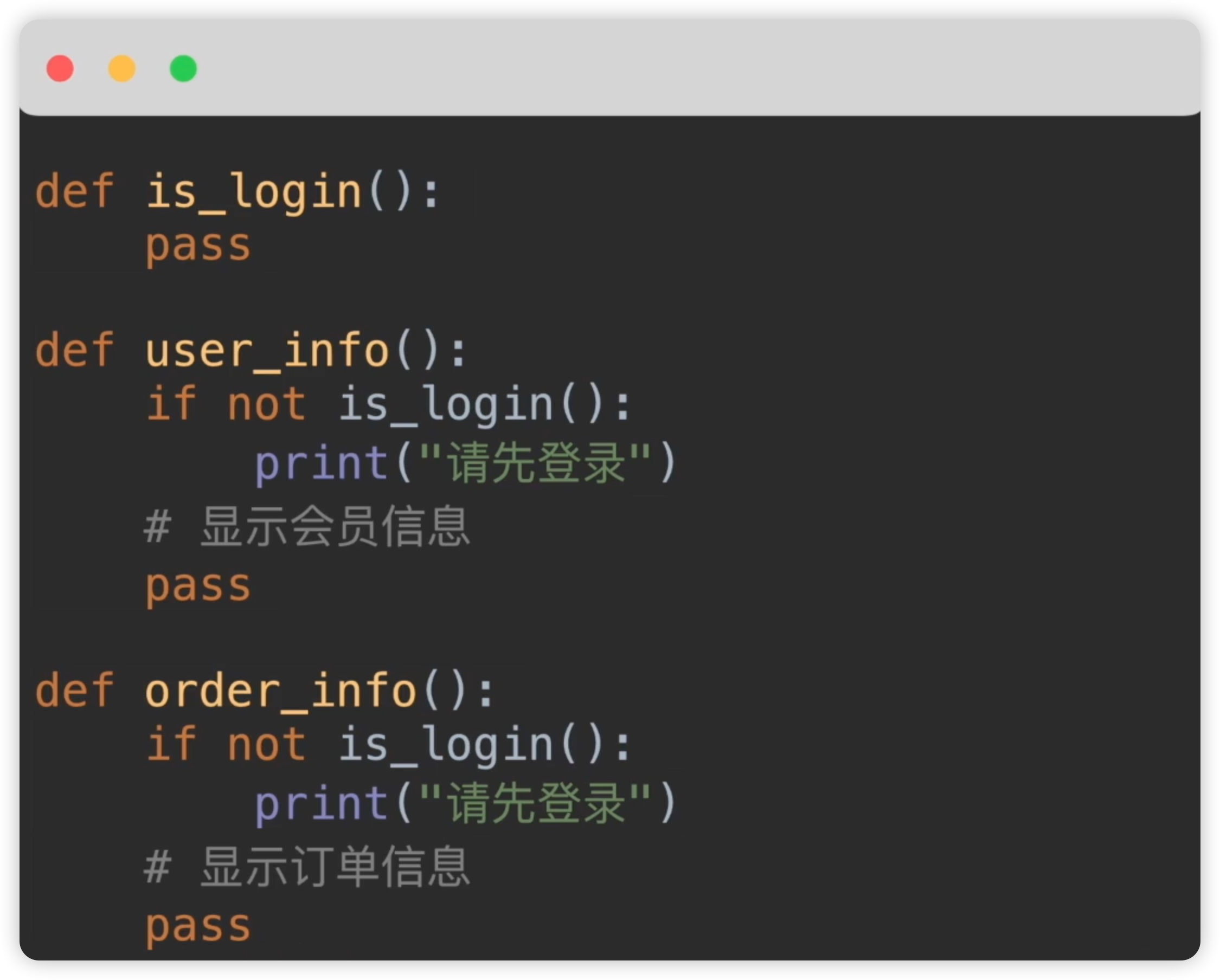
某些功能需要用户登录后才能访问,比如用户信息和订单信息。假设我们有一个判断用户是否登录的函数 is_login,那么在需要用户权限的地方,每个函数内都需要加上这样的判断。比如在 user_info 函数中,我们需要判断用户是否已登录,如果没有登录,则提示用户先登录。同样,在 order_info 函数中也需要进行相同的判断。在一个商城系统中,需要用户权限的地方可能非常多,例如修改密码、邮箱、手机号,以及查看订单详情等。按照上述方式,我们就需要在每个函数内都来判断用户是否已登录,这种方式显然是不可取的。针对这样的问题,我们可以使用函数装饰器来解决。
下面我们将在代码中演示如何使用函数装饰器。首先,我们创建一个名为"decorator"的文件。装饰器的主要作用是改变函数的行为,而不需要修改函数本身的定义。我们先来看一下不使用装饰器使用普通函数,以计算函数的运行时��间为例。
# 导入时间模块
import time
# 定义一个名为for_loop的函数,用于执行一个简单的for循环
def for_loop():
# 输出提示信息,表示函数开始执行
print("for_Loop函数开始")
# 执行一个简单的for循环
for i in range(10000):
pass
# 输出提示信息,表示函数执行结束
print("for_loop函数结束")
# 记录函数开始执行的时间
start_time = time.perf_counter()
# 调用for_loop函数
for_loop()
# 记录函数结束执行的时间
end_time = time.perf_counter()
# 计算并输出for_loop函数的运行时间
print(f"for_Loop函数运行时间:{end_time - start_time}")
这是一个最基本的用法,但如果有多个函数需要计算执行时间,这样的操作就显得繁琐。当我们学习函数时,我们谈到了函数可以实现代码的重用。因此,我们可以使用函数的方式来实现这种功能。
接下来重新�编写一个函数。我们定义一个名为my_decorator的函数,作为装饰器。在这个函数内部,我们传递一个参数func,这个参数实际上是一个函数。我们知道函数可以作为参数传递。接着,我们在函数内部可以实现函数嵌套,使用def再来定义一个函数,命名为wrapper然后实现计时功能。代码如下:
import time
# 定义一个函数装饰器
def my_decorator(func):
# 定义装饰器函数内部的包装函数
def wrapper():
print("wrapper函数开始")
# 记录函数开始时间
start_time = time.perf_counter()
# 调用被装饰的函数
func()
# 记录函数结束时间
end_time = time.perf_counter()
# 打印函数运行时间
print(f"函数运行时间:{end_time - start_time}")
print("wrapper函数结束")
return wrapper
# 定义一个简单的函数
def for_loop() :
print("for_Loop函数开始")
# 一个简单的循环
for i in range(10000):
pass
print("for_loop函数结束")
# 将函数for_loop使用装饰器进行装饰
new_for = my_decorator(for_loop) # 新函数 new_for 等于 wrapper 函数
# 调用被装饰后的函数
new_for()
在执行代码时,程序由上至下执行。首先导入time模块,然后创建my_decorator和for_loop的函数对象。继续向下执行,调用my_decorator函数,并传递参数。程序将控制权交给my_decorator函数,即进入my_decorator函数内部。在这里,func是我们传递的参数for_loop。程序继续向下执行,又遇到了一个def,同样地定义了一个wrapper函数对象,但不会执行函数体内的内容。继续向下执行,遇到return,将wrapper返回给my_decorator函数的调用者,即接收到wrapper函数。然后将其赋值给一个新的变量new_for,这个new_for实际上就是wrapper。接着调用这个函数,即new_for(),完成整个过程。
当我们调用这个函数时,就会执行wrapper函数。wrapper函数的内容是输出函数开始,然后计时,接着调用函数,执行完毕后输出函数结束,最后输出函数运行时间。输出结果如下:
wrapper函数开始
for_Loop函数开始
for_loop函数结束
函数运行时间:0.00024348200531676412
wrapper函数结束
这是一个关于函数调用的示例。在调用其他函数时,我们可以采取相似的方法。例如,我们定义了一个名为 while_loop 的函数。代码如下:
import time
# 定义一个函数装饰器
def my_decorator(func):
# 定义装饰器函数内部的包装函数
def wrapper():
print("wrapper函数开始")
# 记录函数开始时间
start_time = time.perf_counter()
# 调用被装饰的函数
func()
# 记录函数结束时间
end_time = time.perf_counter()
# 打印函数运行时间
print(f"函数运行时间:{end_time - start_time}")
print("wrapper函数结束")
return wrapper
# 定义一个简单的函数
def for_loop() :
print("for_Loop函数开始")
# 一个简单的循环
for i in range(10000):
pass
print("for_loop函数结束")
# 将函数for_loop使用装饰器进行装饰
new_for = my_decorator(for_loop) # 新函数 new_for 等于 wrapper 函数
# 调用被装饰后的函数
new_for()
def while_loop():
print("while_loop函数开始")
i = 0
while i < 10000:
i+=1
print("while_loop函数结束")
new_while = my_decorator(while_loop)
new_while()
输出结果:
wrapper函数开始
for_Loop函数开始
for_loop函数结束
函数运行时间:0.000243259004491847
wrapper函数结束
wrapper函数开始
while_loop函数开始
while_loop函数结束
函数运行时间:0.0005650989987771027
wrapper函数结束
观察输出结果。前面输出的是 for 循环的运行时间,下面输出的是 while 循环的运行时间。如果需要计算其他函数的运行时间,也是类似的调用方式。这里我们使用了普通的函数来实现这个功能,但是 Python 中提供了一种更简洁的方式,称为装饰器。
在介绍装饰器之前,我们先简化了 my_decorator 和 for_loop 函数。现在,我们将这段代码转化为装饰器的形式。如下图所指示:
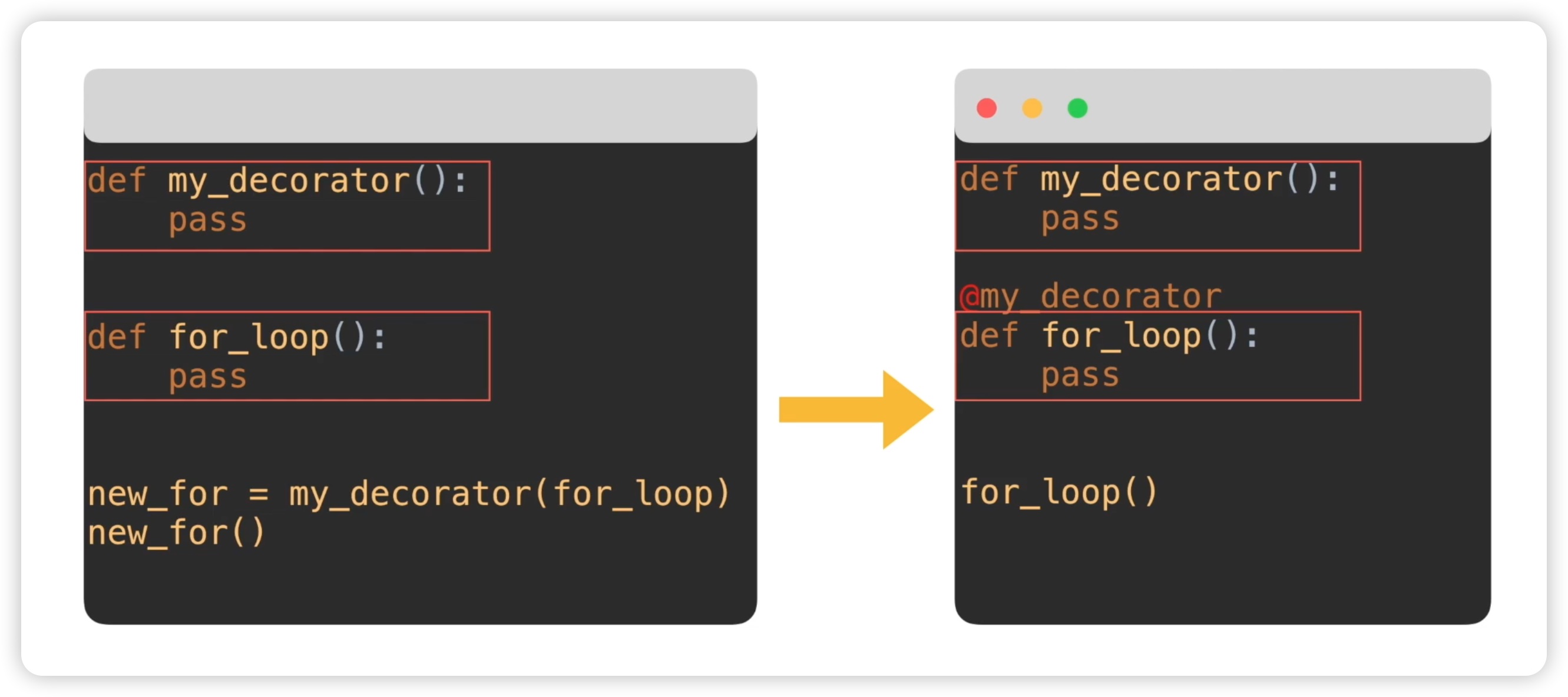
my_decorator 函数保持不变,for_loop 函数也保持不变,但是在 for_loop 函数上方,我们添加了一个 @ 符号,后跟 my_decorator。这个语法格式可能看起来有些奇怪,但它是 Python 中的装饰器。@ 符号有时被称为语法糖,因为它能让代码更加简洁。使用了语法糖后,左侧普通函数调用的方式需要传递参数并使用 my_decorator 函数来装饰函数。而在右侧,由于使用了语法糖,调用函数时只需直接调用原函数名即可,这使得代码更加简洁易读。这种结构使用装饰器能够使得代码更加简洁、易读,因为我们仍然使用原始的函数,而 my_decorator 函数仅用于装饰目标函数。
接下来,我们使用装饰器来改造原来的代码。很简单,只需在 for_loop 函数上方添加 @ 符号,并加上 my_decorator,表示 for_loop 函数被 my_decorator 函数装饰。装饰后,我们就不需要像以前那样调用装饰器函数了,而是直接调用原函数即可。同样地,我们也可以修改 while loop 的部分,加上 @my_decorator,直接调用 while_loop 函数,代码如下:
import time
# 定义装饰器函数
def my_decorator(func):
# 定义包裹函数
def wrapper():
print("wrapper函数开始") # 输出包裹函数开始
start_time = time.perf_counter() # 记录开始时间
func() # 调用被装饰的函数
end_time = time.perf_counter() # 记录结束时间
print(f"函数运行时间:{end_time - start_time}") # 输出函数运行时间
print("wrapper函数结束") # 输出包裹函数结束
return wrapper # 返回包裹函数
# 使用装饰器修饰for_loop函数
@my_decorator
def for_loop():
print("for_loop函数开始") # 输出for_loop函数开始
for i in range(10000): # 执行for循环
pass
print("for_loop函数结束") # 输出for_loop函数结束
# 使用装饰器修饰while_loop函数
@my_decorator
def while_loop():
print("while_loop函数开始") # 输出while_loop函数开始
i = 0
while i < 10000: # 执行while循环
i+=1
print("while_loop函数结束") # 输出while_loop函数结束
# 调用被装饰的for_loop函数
for_loop()
# 调用被装饰的while_loop函数
while_loop()
输出结果:
wrapper函数开始
for_loop函数开始
for_loop函数结束
函数运行时间:0.0002862349938368425
wrapper函数结束
wrapper函数开始
while_loop函数开始
while_loop函数结束
函数运行时间:0.000561889995879028
wrapper函数结束
运行结果也会相同。这就是函数装饰器的作用。装饰器通过装饰器函数来修改原来函数的功能,使得原函数无需修改即可实现新的功能。
带参数的函数装饰器
在上一节课中,我们介绍了函数的装饰器。我们装饰的一个函数是非常简单的一个函数,名为for_loop。这个函数没有任何参数。在本节中,我们将介绍稍微复杂一点的形式,带有参数的装饰器。接下来我们将直接在代码中演示。我们新建一个Python文件,命名为decorater_args.py,其中args表示带参数的意思。然后我们复制上节的代码,即被装饰的函数for_loop,现在我们给它添加一个参数,命名为number,并用它来替换10000,这样在调用这个函数时,就可以自定义循环的次数。比如,如果number是1000,就表示循环1000次。代码如下:
import time
# 定义装饰器函数
def my_decorator(func):
# 定义包裹函数
def wrapper():
print("wrapper函数开始") # 输出包裹函数开始
start_time = time.perf_counter() # 记录开始时间
func() # 调用被装饰的函数
end_time = time.perf_counter() # 记录结束时间
print(f"函数运行时间:{end_time - start_time}") # 输出函数运行时间
print("wrapper函数结束") # 输出包裹函数结束
return wrapper # 返回包裹函数
# 使用装饰器修饰for_loop函数
@my_decorator
def for_loop(number):
print("for_loop函��数开始") # 输出for_loop函数开始
for i in range(number): # 执行for循环
pass
print("for_loop函数结束") # 输出for_loop函数结束
# 使用装饰器修饰while_loop函数
@my_decorator
def while_loop():
print("while_loop函数开始") # 输出while_loop函数开始
i = 0
while i < 10000: # 执行while循环
i+=1
print("while_loop函数结束") # 输出while_loop函数结束
# 调用被装饰的for_loop函数
for_loop()
# 调用被装饰的while_loop函数
while_loop()
现在我们对这个for_loop函数添加了一个参数,接下来我们需要相应地修改my_decorator装饰器函数。my_decorator函数有一个参数func,它就是被装饰的函数,也就是我们这里的for_loop。既然for_loop里调用了一个参数,那么下面的for_loop函数肯定也应该有一个参数number。现在这里显示一个波浪线,说明这个参数还没有定义。这个参数应该由谁传递呢?如下图所示:
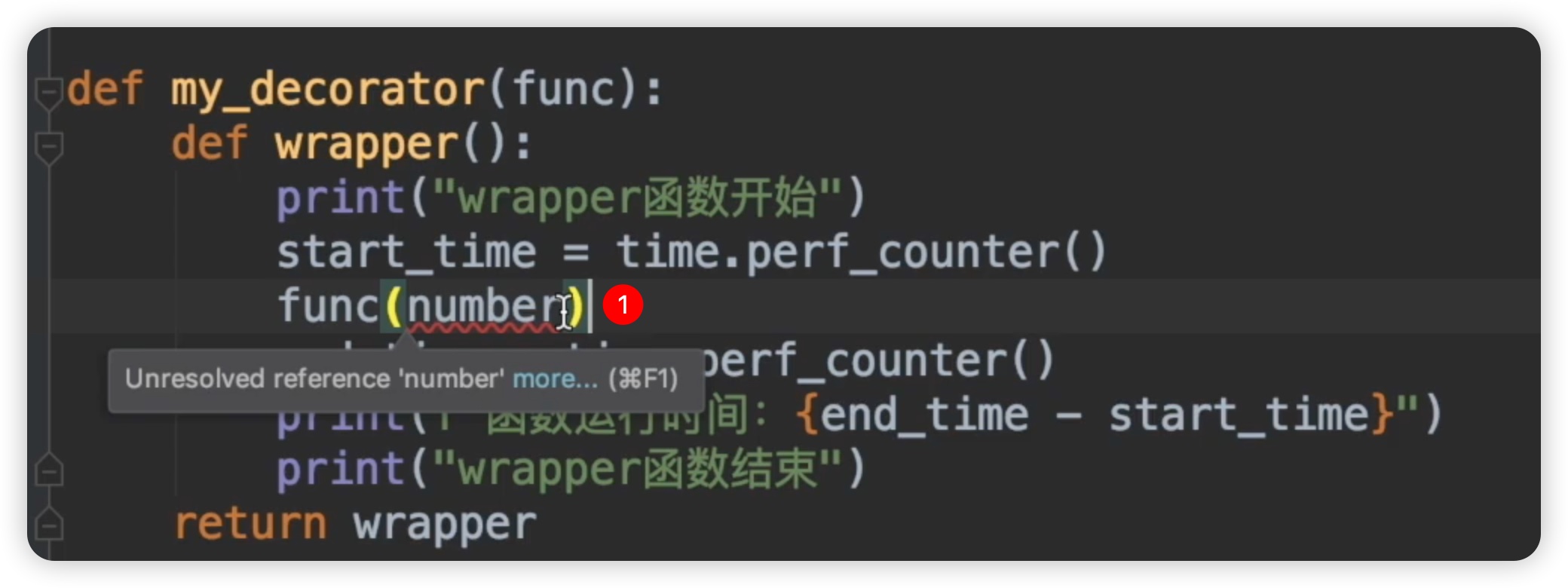
这里只有两处,一个是在wrapper函数这里传递一个参数,另一处是在my_decorator这里传递一个参数。首先,我们尝试将参数加到my_decorator函数这里看一下会有什么效果。如下图所示:
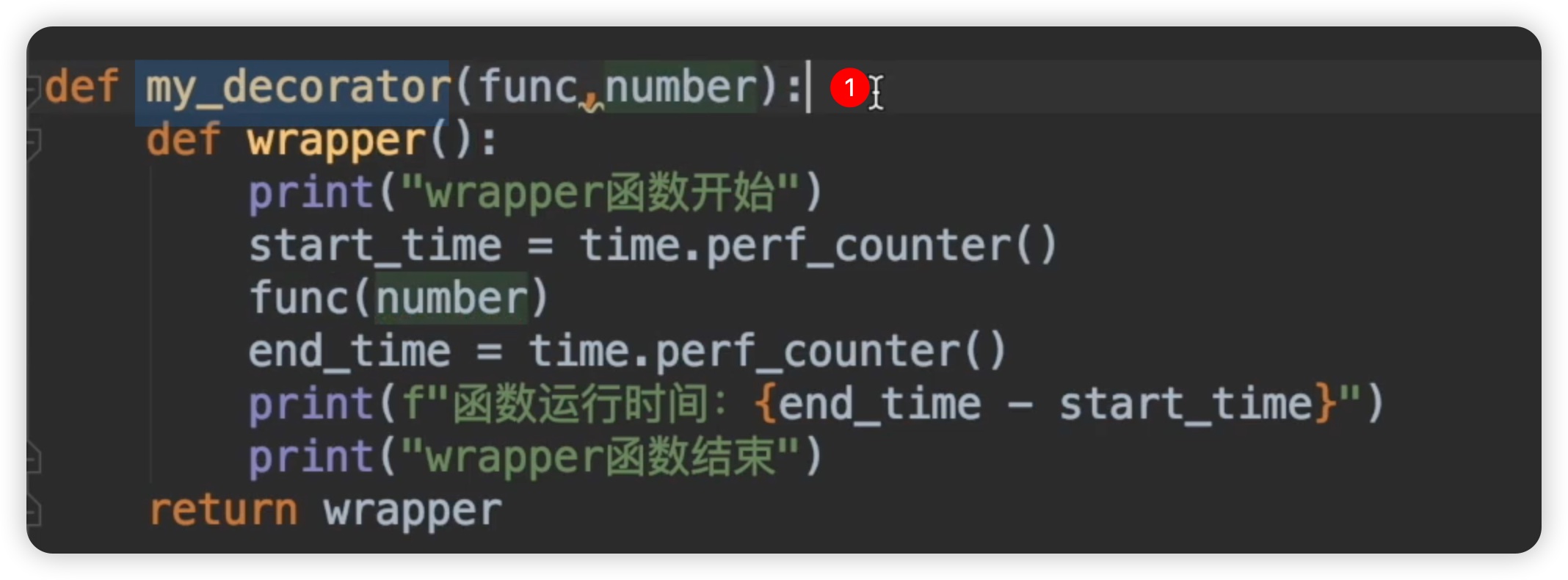
首先来找到谁调用了my_decorator。由于我们使用的装饰器,让我们看一下之前被注释的代码,它更容易理解。如下图所示:
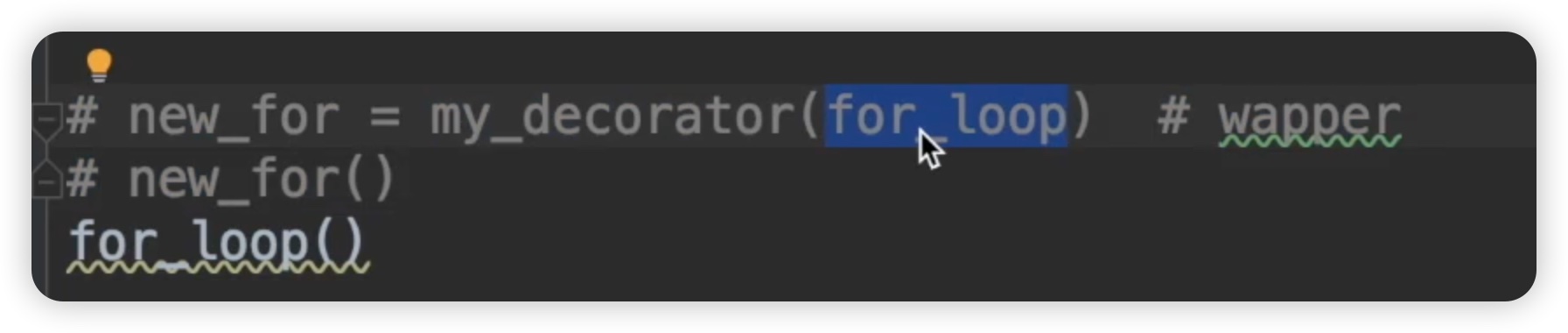
由于这个函数有两个参数,第一个参数是被装饰的函数,第二个参数我们假设是number,也就是这个函数的参数。当我们调用这里的时候,my_decorator最后返回的是一个wrapper函数对象,我们又将这个wrapper赋值给new_for。在下面这行代码,它等价于wrapper(),即调用wrapper。当调用wrapper的时候,此时这个函数并没有接收到number,所以它会报错。那也就是说第一种情况是行不通的,number不应该放到my_decorator函数的参数里。我们把它删除掉,那就是第二种情况了,number放到wrapper函数这里。
如下图所示:
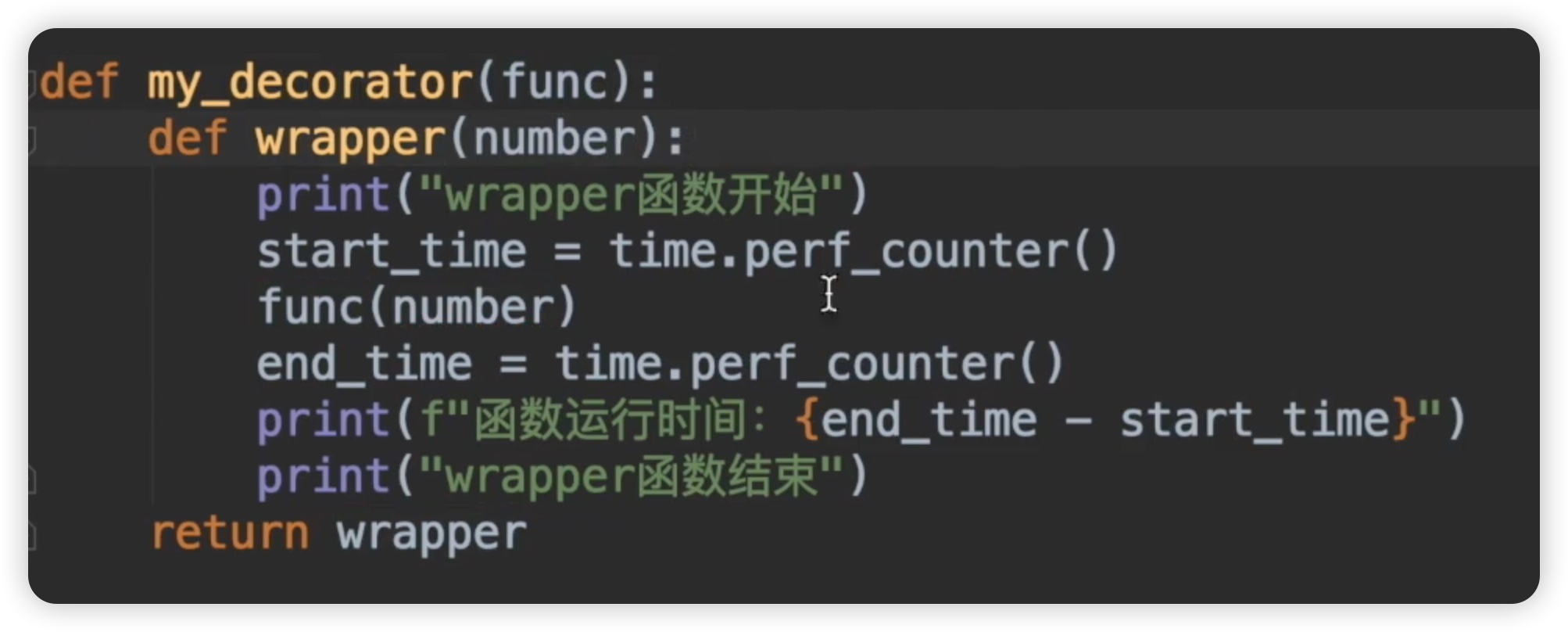
此时我们再来分析一下。当调用my_decorator的时候,这里没有number,返回的结果是一个wrapper对象。下一行是调用这个wrapper函数,也就是调用这里的wrapper函数,wrapper函数这里有个number,这个number是谁传递的呢?就应该是我们这里的new_for。这里应该给它传递一个number,我们设设置number为100000。代码如下:
import time
# 定义装饰器函数
def my_decorator(func):
# 定义包裹函数
def wrapper(number):
print("wrapper函数开始")
# 记录函数开始时间
start_time = time.perf_counter()
# 调用被装饰的函数
func(number)
# 记录函数结束时间
end_time = time.perf_counter()
# 输出函数运行时间
print(f"函数运行时间:{end_time - start_time}")
print("wrapper函数结束")
return wrapper
def for_loop(number):
print("for_loop函数开始")
# 执行for循环
for i in range(number):
pass
print("for_loop函数结束")
# 使用装饰器调用for循环函数
new_for = my_decorator(for_loop) # wrapper
new_for(100000) # wrapper(100000)
输出结果:
wrapper函数开始
for_loop函数开始
for_loop函数结束
函数运行时间:0.002449886000249535
wrapper函数结束
先使用我们最原始的方式,在调用的时候,我们看一下最原始的方式,它就表示wrapper函数调用的时候传递一个参数100000。结果可以正常显示。
那如果我们使用装饰器的方式呢,代码如下:
import time
# 定义装饰器函数
def my_decorator(func):
# 定义包裹函数
def wrapper(number):
print("wrapper函数开始")
# 记录函数开始时间
start_time = time.perf_counter()
# 调用被装饰的函数
func(number)
# 记录函数结束时间
end_time = time.perf_counter()
# 输出函数运行时间
print(f"函数运行时间:{end_time - start_time}")
print("wrapper函数结束")
return wrapper
@my_decorator
def for_loop(number):
print("for_loop函数开始")
# 执行for循环
for i in range(number):
pass
print("for_loop函数结束")
for_loop(100000)
对于while循环,这里也是一样的,代码如下:
import time
# 定义装饰器函数
def my_decorator(func):
# 定义包裹函数
def wrapper(number):
print("wrapper函数开始")
# 记录函数开始时间
start_time = time.perf_counter()
# 调用被装饰的函数
func(number)
# 记录函数结束时间
end_time = time.perf_counter()
# 输出函数运行时间
print(f"函数运行时间:{end_time - start_time}")
print("wrapper函数结束")
return wrapper
# 被装饰的for循环函数
@my_decorator
def for_loop(number):
print("for_loop函数开始")
# 执行for循环
for i in range(number):
pass
print("for_loop函数结束")
# 被装饰的while循环函数
@my_decorator
def while_loop(number):
print("while_loop函数开始")
# 执行while循环
i = 0
while i < number:
i+=1
print("while_loop函数结束")
# 调用被装饰的for循环函数
for_loop(100000)
# 调用被装饰的while循环函数
while_loop(100000)
这就是为装饰器添加参数的形式。我们再来总结一下:如果被装饰的函数里有参数,那么你在装饰器中就应该添加一个参数,这个参数应该作为里层函数的参数进行传递,因为我们使用装饰器最终返回的是一个wrapper函数对象,这个对象就等价于你这里的for_loop。当我们调用这里的for_loop函数的时候,就相当于调用这里的wrapper函数,那原函数中有一个参数,wrapper函数中,这里就应该有一个参数,最后这里的参数就会传递给原来的for_loop函数。
不定长参数的函数装饰器
在上一节课程中,我们介绍了带有参数的装饰器。我们知道在定义函数时,还有一种参数称为可变参数��。在本节中,我们将介绍带有可变参数的装饰器。前面在学习可变参数时,我们使用了一个 * 号加上 args 来表示接收一个元组,以及使用两个 ** 号加 kwargs 来表示接收一个字典。
 针对带有可变参数的函数,我们学习如何使用装饰器进行装饰。接下来我们通过代码演示。首先,我们复制之前介绍带有参数的装饰器的代码,稍作修改,将其命名为 decorator_args_and_kwargs。代码如下:
针对带有可变参数的函数,我们学习如何使用装饰器进行装饰。接下来我们通过代码演示。首先,我们复制之前介绍带有参数的装饰器的代码,稍作修改,将其命名为 decorator_args_and_kwargs。代码如下:
import time
def my_decorator(func):
# 定义装饰器函数
def wrapper(number):
print("wrapper函数开始") # 输出开始执行wrapper函数的信息
start_time = time.perf_counter() # 记录函数开始执行的时间
func(number) # 调用原始函数
end_time = time.perf_counter() # 记录函数执行结束的时间
print(f"函数运行时间:{end_time - start_time}") # 输出函数执行时间
print("wrapper函数结束") # 输出wrapper函数执行结束的信息
return wrapper # 返回wrapper函数作为装饰器
def welcome(*args):
name, gender = args # 使用元组解包获取传入参数
if gender == "男":
gender = "先生" # 若性别为男,则称呼为先生
else:
gender = "女士" # 若性别不为男,则称呼为女士
print(f"hi {name}{gender},welcome to daxiong course") # 输出欢迎信息
welcome("Andy", "男") # 调用函数并传入参数
至此,我们已经展示了如何处理带有一个可变参数的函数。
现在,我们将使用装饰器来装饰这个函数。使用装饰器非常简单,只需要在函数定义前加上 @ 符号,后跟装饰它的函数名称,即 my_decorator。由于函数的参数是一个可��变参数,因此我们需要修改 my_decorator 的参数为 * args。代码如下:
import time
def my_decorator(func):
# 定义装饰器函数
def wrapper(*args):
print("wrapper函数开始") # 输出开始执行wrapper函数的信息
start_time = time.perf_counter() # 记录函数开始执行的时间
func(*args) # 调用原始函数
end_time = time.perf_counter() # 记录函数执行结束的时间
print(f"函数运行时间:{end_time - start_time}") # 输出函数执行时间
print("wrapper函数结束") # 输出wrapper函数执行结束的信息
return wrapper # 返回wrapper函数作为装饰器
@my_decorator
def welcome(*args):
name, gender = args # 使用元组解包获取传入参数
if gender == "男":
gender = "先生" # 若性别为男,则称呼为先生
else:
gender = "女士" # 若性别不为男,则称呼为女士
print(f"hi {name}{gender},welcome to daxiong course") # 输出欢迎信息
welcome("Andy", "男") # 调用函数并传入参数
输出结果:
wrapper函数开始
hi Andy先生,welcome to daxiong course
函数运行时间:6.119997124187648e-06
wrapper函数结束
可以看到输出结果依然是正确的。至此,我们已经成功地使用装饰器装饰了一个带有可变参数的函数。接下来,让我们进一步优化代码。我们可以将 if else 语句简化成一行代码。通过对 gender 的赋值来判断是先生还是女士,我们可以将代码精简为一行,提高了代码的简洁性。代码如下:
import time
def my_decorator(func):
# 定义装饰器函数
def wrapper(*args):
print("wrapper函数开始") # 输出开始执行wrapper函数的信息
start_time = time.perf_counter() # 记录函数开始执行的时间
func(*args) # 调用原始函数
end_time = time.perf_counter() # 记录函数执行结束的时间
print(f"函数运行时间:{end_time - start_time}") # 输出函数执行时间
print("wrapper函数结束") # 输出wrapper函数执行结束的信息
return wrapper # 返回wrapper函数作为装饰器
@my_decorator
def welcome(*args):
name, gender = args # 使用元组解包获取传入参数
gender = "男士" if gender == "男" else "女士"
print(f"hi {name}{gender},welcome to daxiong course") # 输出欢迎信息
welcome("Andy", "男") # 调用函数并传入参数
结果一样可以正常输出,这是使用不定长参数的元组的形式 如果 welcome 函数还接收其他参数,比如年龄和爱好,我们需要使用字典来接收这些参数。这时,我们可以使用两个 * 号 kwargs 来接收。然后,我们通过字典的键名来获取相应的值,代码如下:
import time
def my_decorator(func):
# 定义装饰器函数
@functools.wraps(func)
def wrapper(*args, **kwargs):
print("wrapper函数开始") # 输出开始执行wrapper函数的信息
start_time = time.perf_counter() # 记录函数开始执行的时间
func(*args, **kwargs) # 调用原始函数
end_time = time.perf_counter() # 记录函数执行结束的时间
print(f"函数运行时间:{end_time - start_time}") # 输出函数执行时间
print("wrapper函数结束") # 输出wrapper函数执行结束的信息
return wrapper # 返回wrapper函数作为装饰器
@my_decorator
def welcome(*args, **kwargs):
name, gender = args # 使用元组解包获取传入参数
gender = "男士" if gender == "男" else "女士" # 根据性别设置称呼
print(f"hi {name}{gender},welcome to daxiong course") # 输出欢迎信息
print(f"{name}的年龄:{kwargs['age']}") # 输出姓名对应的年龄
print(f"{name}的爱好:{kwargs['hobby']}") # 输出姓名对应的爱好
welcome("Andy", "男", age="18", hobby="basketball") # 调用函数并传入参数
输出结果:
wrapper函数开始
hi Andy男士,welcome to daxiong course
Andy的年龄:18
Andy的爱好:basketball
函数运行时间:1.5914003597572446e-05
wrapper函数结束
需要注意的是,在获取键名时,我们使用了单引号,以避免与外部双引号混淆。可以看到输出结果依然是正确的。至此,我们完成了对带有不定长参数的函数的装饰。
被装饰的函数改变了吗?
在前述部分关于装饰器的介绍中,我们提到了被装饰的函数,指的是它的形式和作用没有发生改变。这里所谓的“没有被改变”,指的是函数的形式和作用没有变化。那么,这个函数的本身是否发生了改变呢?函数的元信息是否有所改变呢?在代码中直接看一下被装饰的函数是否发生了改变。在这段代码中,函数 welcome 被装饰了。我们来看一下它是否发生了改变。一种直观的方式是先将装饰器注释掉,然后在不使用装饰器的情况下输出这个函数。代码如下:
import time
def my_decorator(func):
# 定义装饰器函数
def wrapper(*args, **kwargs):
print("wrapper函数开始") # 输出开始执行wrapper函数的信息
start_time = time.perf_counter() # 记录函数开始执行的时间
func(*args, **kwargs) # 调用原始函数
end_time = time.perf_counter() # 记录函数执行结束的时间
print(f"函数运行时间:{end_time - start_time}") # 输出函数执行时间
print("wrapper函数结束") # 输出wrapper函数执行结束的信息
return wrapper # 返回wrapper函数作为装饰器
#@my_decorator
def welcome(*args, **kwargs):
name, gender = args # 使用元组解包获取传入参数
gender = "男士" if gender == "男" else "女士" # 根据性别设置称呼
print(f"hi {name}{gender},welcome to daxiong course") # 输出欢迎信息
print(f"{name}的年龄:{kwargs['age']}") # 输出姓名对应的年龄
print(f"{name}的爱好:{kwargs['hobby']}") # 输出姓名对应的爱好
welcome("Andy", "男", age="18", hobby="basketball") # 调用��函数并传入参数
print(welcome)
输出结果:
hi Andy男士,welcome to daxiong course
Andy的年龄:18
Andy的爱好:basketball
<function welcome at 0x107e98160>
输出结果是一个函数对象,名字是 welcome。现在我们添加装饰器,再来输出。结果显示输出的结果也是一个函数对象,但它发生了变化。
<function my_decorator.<locals>.wrapper at 0x105034280>
变成了装饰器下面的 wrapper 函数。为了更清晰地表述这个问题,我们可以使用函数对象的一个属性,即 .__name__,它代表着函数对象的名称。代码如下:
import time
def my_decorator(func):
# 定义装饰器函数
def wrapper(*args, **kwargs):
print("wrapper函数开始") # 输出开始执行wrapper函数的信息
start_time = time.perf_counter() # 记录函数开始执行的时间
func(*args, **kwargs) # 调用原始函数
end_time = time.perf_counter() # 记录函数执行结束的时间
print(f"函数运行时间:{end_time - start_time}") # 输出函数执行时间
print("wrapper函数结束") # 输出wrapper函数执行结束的信息
return wrapper # 返回wrapper函数作为装饰器
@my_decorator
def welcome(*args, **kwargs):
name, gender = args # 使用元组解包获取传入参数
gender = "男士" if gender == "男" else "女士" # 根据性别设置称呼
print(f"hi {name}{gender},welcome to daxiong course") # 输出欢迎信息
print(f"{name}的年龄:{kwargs['age']}") # 输出姓名对应的年龄
print(f"{name}的爱好:{kwargs['hobby']}") # 输出姓名对应的爱好
welcome("Andy", "男", age="18", hobby="basketball") # 调用函数并传入参数
print(welcome.__name__)
输出结果:
wrapper函数开始
hi Andy男士,welcome to daxiong course
Andy的年龄:18
Andy的爱好:basketball
函数运行时间:1.4263998309616e-05
wrapper函��数结束
wrapper
在使用装饰器的情况下,我们输出一下,结果是一个 wrapper 函数,也就是说,这里的 welcome 它变成了 wrapper 函数。如果不使用装饰器,再来运行,结果是 welcome,这才是原来函数的内容。因此,使用装饰器会改变原来函数的元信息。在大多数情况下,我们可能并不需要这个元信息,因为对结果没有影响。但有时我们需要保留它的元信息,这时我们就不能直接使用装饰器的形式了。
为了解决这个问题,通常我们会使用一个内置的装饰器,叫做 functools.wraps。为了保存被装饰函数的元信息,代码如下:
import time
import functools
# 定义装饰器函数
def my_decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print("wrapper函数开始")
start_time = time.perf_counter()
func(*args, **kwargs)
end_time = time.perf_counter()
print(f"函数运行时间:{end_time - start_time}")
print("wrapper函数结束")
return wrapper
# 使用装饰器修饰welcome函数
@my_decorator
def welcome(*args, **kwargs):
name, gender = args
gender = "男士" if gender == "男" else "女士"
print(f"hi {name}{gender},welcome to daxiong course")
print(f"{name}的年龄:{kwargs['age']}")
print(f"{name}的爱好:{kwargs['hobby']}")
# 调用被装饰的welcome函数
welcome("Andy", "男", age="18", hobby="basketball")
# 输出函数的名称,通过functools.wraps保留原函数的元信息
print(welcome.__name__) # 输出 welcome
现在我们再来看一下此时 welcome.name 它输出的结果是什么?如果输出的结果是 welcome,那么就表示它保存了元信息;如果输出的结果是 wrapper,那么就说明它没有保存元信息。
输出结果:
wrapper函数开始
hi Andy男士,welcome to daxiong course
Andy的年龄:18
Andy的爱好:basketball
函数运行时间:1.5636003809049726e-05
wrapper函数结束
welcome
现在我们来运行,结果显示输出的结果是 welcome。所以说,使用 functools.wraps 这个装饰器成功地保存了被装饰函数的元信息。如果我把它注释掉,再来运行,看到这里就输出了 wrapper,没有保存元信息。这就是本节我们要介绍的内容,只用 functools 这个模块下面的方法来保存被装饰函数的元信息。
函数装饰器嵌套
在本节中,我们将介绍装饰器的嵌套形式。装饰器嵌套指的是在一个函数上应用多个装饰器的情况。例如,我们有一个名为func的函数,在该函数上应用了三个装饰器,分别是decorator1、decorator2和decorator3,形成了装饰器的嵌套形式。如下图所示:
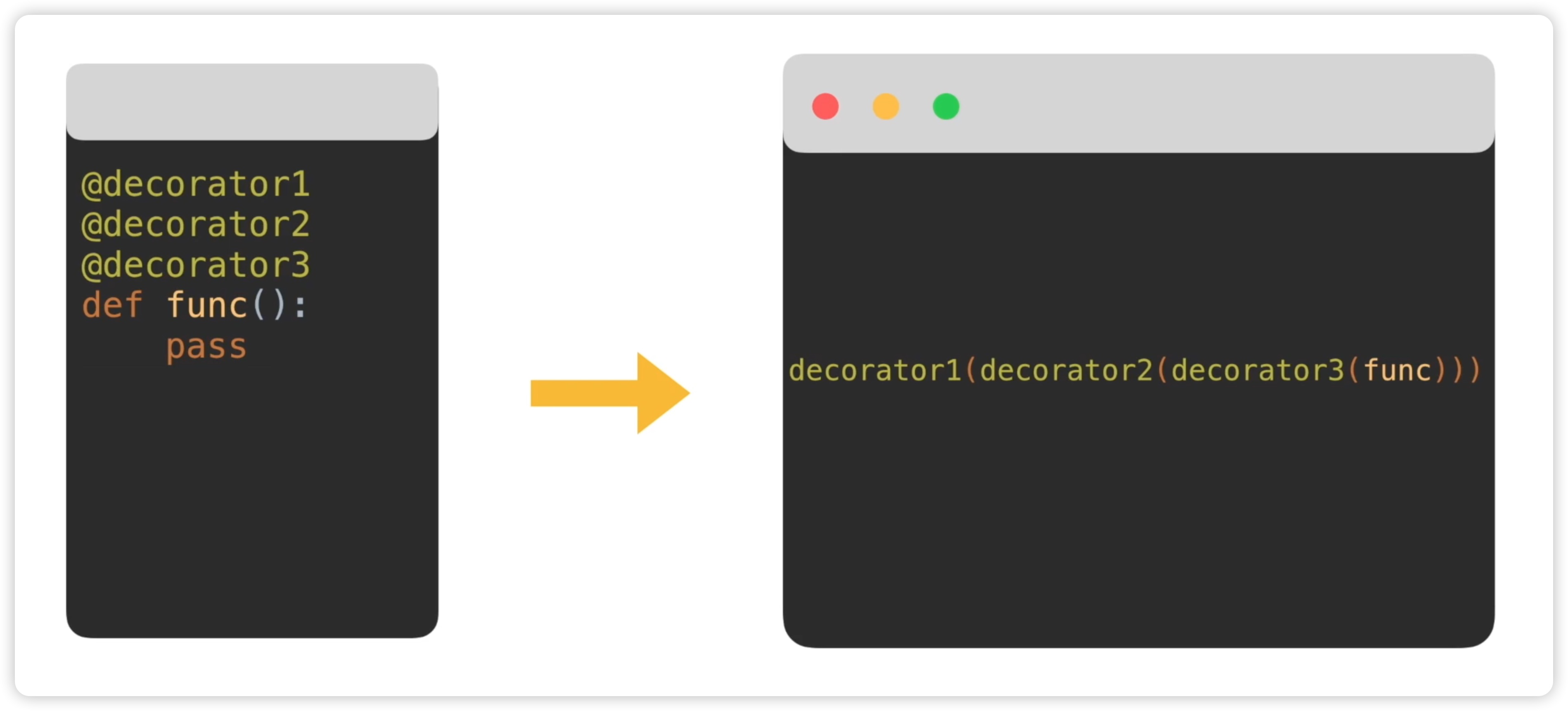
这段代码的等价形式可以用一行代码表示。我们将重点关注函数调用的顺序,首先是使用decorator3装饰func函数,然后使用decorator2装饰其结果,最后使用decorator1装饰前面生成的结果。装饰器的调用顺序是由里层向外层依次装饰的。
在代码示例中,我们创建了一个Python文件,命名为nested_decorator.py,用于演示装饰器的嵌套。首先,我们导入了functools模块,然后定义了第一个装饰器decorator1,它接收一个被装饰的函数func,并使用functools.wraps来保留被装饰函数的原信息。接着定义了一个wapper函数,输出执行装饰器1的信息,并调用func函数。装饰器1定义完成后,我们复制了一份代码来定义第二个装饰器decorator2。在decorator2中,我们定义了一个名为welcome的函数,接收一个参数message,并输出该信息。代码如下:
import functools # 导入 functools 模块,用于装饰器的处理
def decorator1(func): # 定义装饰器1,接受一个函数作为参数
@functools.wraps(func) # 使用 functools 的 wraps 装饰器,保留原函数的元数据
def wrapper1(*args, **kwargs): # 定义装饰器1内部的包装函数,接受任意数量的位置参数和关键字参数
print("执行装饰器1") # 输出装饰器1执行的信息
func(*args, **kwargs) # 调用被装饰的函数,传递参数
return wrapper1 # 返回包装函数
def decorator2(func): # 定义装饰器2,接受一个函数作为参数
@functools.wraps(func) # 使用 functools 的 wraps 装饰器,保留原函数的元数据
def wrapper2(*args, **kwargs): # 定义装饰器2内部的包装函数,接受任意数量的位置参数和关键字参数
print("执行装饰器2") # 输出装饰器2执行的信息
func(*args, **kwargs) # 调用被装饰的函数,传递参数
return wrapper2 # 返回包装函数
def welcome(message): # 定义欢迎函数,接受一个参数 message
print(message) # 输出欢迎信息
welcome("welcome to daxiong course") # 调用欢迎函数,输出欢迎信息
输出结果:
welcome to daxiong course
上面是没有使用装饰器的情况。接下来我们要使用装饰器。我们在函数上方添加一个"@"符号,然后写上装饰器的名称。首先使用decorator1来装饰。代码如下:
import functools # 导入 functools 模块,用于装饰器的处理
def decorator1(func): # 定义装饰器1,接受一个函数作为参数
@functools.wraps(func) # 使用 functools 的 wraps 装饰器,保留原函数的元数据
def wrapper1(*args, **kwargs): # 定义装饰器1内部的包装函数,接受任意数量的位置参数和关键字参数
print("执行装饰器1") # 输出装饰器1执行的信息
func(*args, **kwargs) # 调用被装饰的函数,传递参数
return wrapper1 # 返回包装函数
def decorator2(func): # 定义装饰器2,接受一个函数作为参数
@functools.wraps(func) # 使用 functools 的 wraps 装饰器,保留原函数的元数据
def wrapper2(*args, **kwargs): # 定义装饰器2内部的包装函数,接受任意数量的位置参数和关键字参数
print("执行装饰器2") # 输出装饰器2执行的信息
func(*args, **kwargs) # 调用被装饰的函数,传递参数
return wrapper2 # 返回包装函数
@decorator1
def welcome(message): # 定义欢迎函数,接受一个参数 message
print(message) # 输出欢迎信息
welcome("welcome to daxiong course") # 调用欢迎函数,输出欢迎信息
输出结果:
执行装饰器1
welcome to daxiong course
这时候输出的结果将会是执行了装饰器1,然后输出"welcome to daxiong course"。这是使用装饰器1进行装饰。现在我们将使用装饰器2来装饰。代码如下:
import functools # 导入 functools 模块,用于装饰器的处理
def decorator1(func): # 定义装饰器1,接受一个函数作为参数
@functools.wraps(func) # 使用 functools 的 wraps 装饰器,保留原函数的元数据
def wrapper1(*args, **kwargs): # 定义装饰器1内部的包装函数,接受任意数量的位置参数和关键字参数
print("执行装饰器1") # 输出装饰器1执行的信息
func(*args, **kwargs) # 调用被装饰的函数,传递参数
return wrapper1 # 返回包装函数
def decorator2(func): # 定义装饰器2,接受一个函数作为参数
@functools.wraps(func) # 使用 functools 的 wraps 装饰器,保留原函数的元数据
def wrapper2(*args, **kwargs): # 定义装饰器2内部的包装函数,接受任意数量的位置参数和关键字参数
print("执行装饰器2") # 输出装饰器2执行的信息
func(*args, **kwargs) # 调用被装饰的函数,传递参数
return wrapper2 # 返回包装函数
@decorator2
def welcome(message): # 定义欢迎函数,接受一个参数 message
print(message) # 输出欢迎信息
welcome("welcome to daxiong course") # 调用欢迎函数,输出欢迎信息
输出结果:
执行装饰器2
welcome to daxiong course
结果将会是执行了装饰器2,然后输出"welcome to daxiong course"。接下来我们考虑两个装饰器的情况,也就是装饰器的嵌套。代码如下:
import functools # 导入 functools 模块,用于装饰器的处理
def decorator1(func): # 定义装饰器1,接受一个函数作为参数
@functools.wraps(func) # 使用 functools 的 wraps 装饰器,保留原函数的元数据
def wrapper1(*args, **kwargs): # 定义装饰器1内部的包装函数,接受任意数量的位置参数和关键字参数
print("执行装饰器1") # 输出装饰器1执行的信息
func(*args, **kwargs) # 调用被装饰的函数,传递参数
return wrapper1 # 返回包装函数
def decorator2(func): # 定义装饰器2,接受一个函数作为参数
@functools.wraps(func) # 使用 functools 的 wraps 装饰器,保留原函数的元数据
def wrapper2(*args, **kwargs): # 定义装饰器2内部的包装函数,接受任意数量的位置参数和关键字参数
print("执行装饰器2") # 输出装饰器2执行的信息
func(*args, **kwargs) # 调用被装饰的函数,传递参数
return wrapper2 # 返回包装函数
@decorator1
@decorator2
def welcome(message): # 定义欢迎函数,接受一个参数 message
print(message) # 输出欢迎信息
welcome("welcome to daxiong course") # 调用欢迎函数,输出欢迎信息
输出结果:
执行装饰器1
执行装饰器2
welcome to daxiong course
输出结果是首先执行装饰器1,然后再执行装饰器2,最后执行函数里面的内容。这其实等价于什么呢?它等价于先调用decorator2,接着调用decorator1,然后将这个结果赋值给一个新的变量"new_welcome"。最终我们要调用"new_welcome",并传入一个参数"message"。代码如下:
import functools # 导入 functools 模块,用于装饰器的处理
def decorator1(func): # 定义装饰器1,接受一个函数作为参数
@functools.wraps(func) # 使用 functools 的 wraps 装饰器,保留原函数的元数据
def wrapper1(*args, **kwargs): # 定义装饰器1内部的包装函数,接受任意数量的位置参数和关键字参数
print("执行装饰器1") # 输出装饰器1执行的信息
func(*args, **kwargs) # 调用被装饰的函数,传递参数
return wrapper1 # 返回包装函数
def decorator2(func): # 定义装饰器2,接受一个函数作为参数
@functools.wraps(func) # 使用 functools 的 wraps 装饰器,保留原函数的元数据
def wrapper2(*args, **kwargs): # 定义装饰器2内部的包装函数,接受任意数量的位置参数和关键字参数
print("执行装饰器2") # 输出装饰器2执行的信息
func(*args, **kwargs) # 调用被装饰的函数,传递参数
return wrapper2 # 返回包装函数
def welcome(message): # 定义欢迎函数,接受一个参数 message
print(message) # 输出欢迎信息
new_welcome = decorator1(decorator2(welcome))
new_welcome("welcome to daxiong course")
输出结果:
执行装饰器1
执行装饰器2
welcome to daxiong course
输出结果是一样的。也就是说,使用装饰器嵌套的形式,首先会使用内层的装饰器进行装饰,然后再使用外层装饰器进行装饰。